par1 <- as.numeric(par1)
par2 <- as.numeric(par2)
if (par1 < 10) par1 = 10
if (par1 > 5000) par1 = 5000
if (par2 < 3) par2 = 3
if (par2 > length(x)) par2 = length(x)
library(lattice)
library(boot)
boot.stat <- function(s)
{
s.mean <- mean(s)
s.median <- median(s)
s.midrange <- (max(s) + min(s)) / 2
c(s.mean, s.median, s.midrange)
}
(r <- tsboot(x, boot.stat, R=par1, l=12, sim='fixed'))
bitmap(file='plot1.png')
plot(r$t[,1],type='p',ylab='simulated values',main='Simulation of Mean')
grid()
dev.off()
bitmap(file='plot2.png')
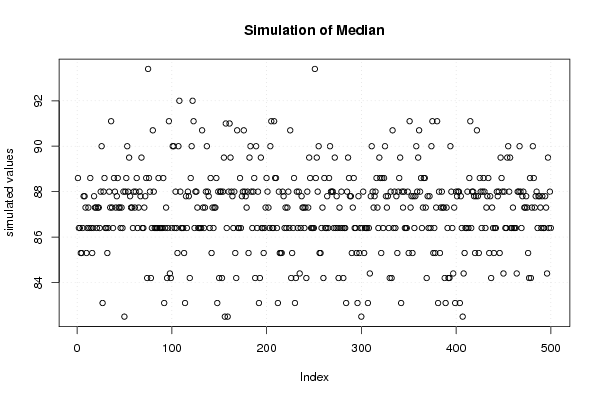
plot(r$t[,2],type='p',ylab='simulated values',main='Simulation of Median')
grid()
dev.off()
bitmap(file='plot3.png')
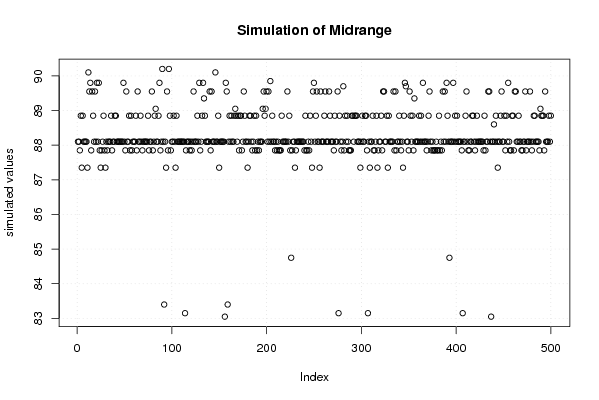
plot(r$t[,3],type='p',ylab='simulated values',main='Simulation of Midrange')
grid()
dev.off()
bitmap(file='plot4.png')
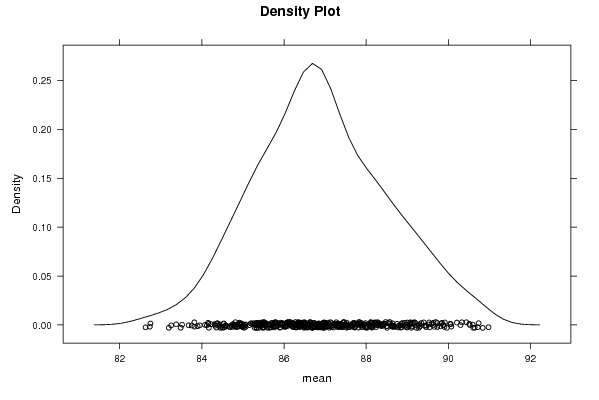
densityplot(~r$t[,1],col='black',main='Density Plot',xlab='mean')
dev.off()
bitmap(file='plot5.png')
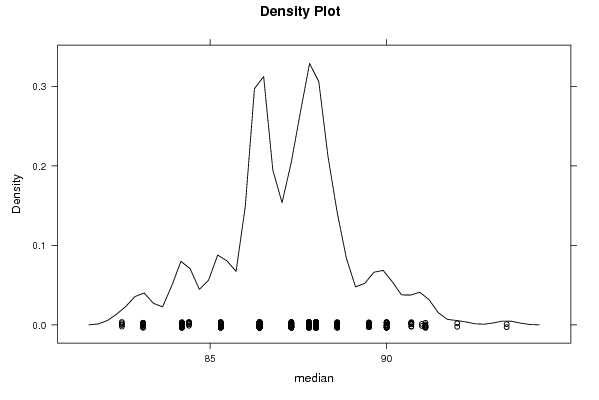
densityplot(~r$t[,2],col='black',main='Density Plot',xlab='median')
dev.off()
bitmap(file='plot6.png')
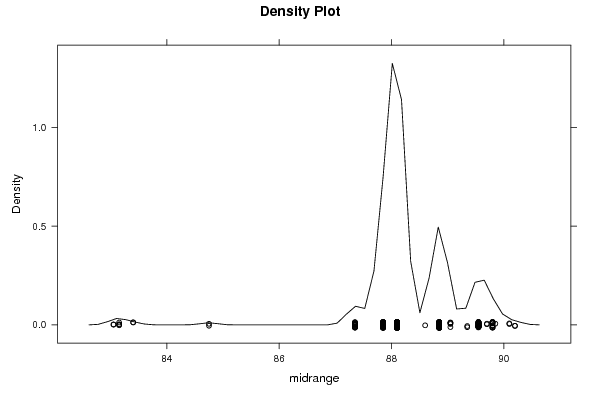
densityplot(~r$t[,3],col='black',main='Density Plot',xlab='midrange')
dev.off()
z <- data.frame(cbind(r$t[,1],r$t[,2],r$t[,3]))
colnames(z) <- list('mean','median','midrange')
bitmap(file='plot7.png')
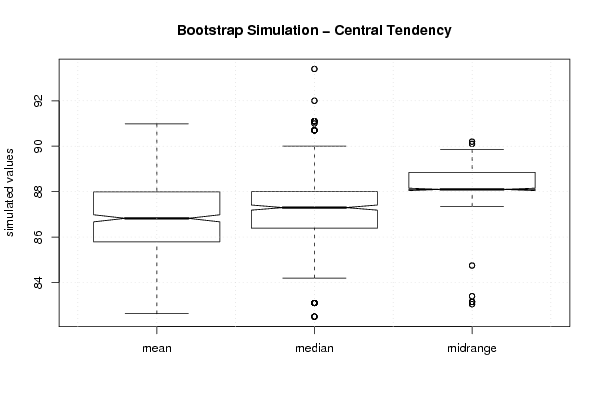
boxplot(z,notch=TRUE,ylab='simulated values',main='Bootstrap Simulation - Central Tendency')
grid()
dev.off()
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Estimation Results of Blocked Bootstrap',6,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'statistic',header=TRUE)
a<-table.element(a,'Q1',header=TRUE)
a<-table.element(a,'Estimate',header=TRUE)
a<-table.element(a,'Q3',header=TRUE)
a<-table.element(a,'S.D.',header=TRUE)
a<-table.element(a,'IQR',header=TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'mean',header=TRUE)
q1 <- quantile(r$t[,1],0.25)[[1]]
q3 <- quantile(r$t[,1],0.75)[[1]]
a<-table.element(a,q1)
a<-table.element(a,r$t0[1])
a<-table.element(a,q3)
a<-table.element(a,sqrt(var(r$t[,1])))
a<-table.element(a,q3-q1)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'median',header=TRUE)
q1 <- quantile(r$t[,2],0.25)[[1]]
q3 <- quantile(r$t[,2],0.75)[[1]]
a<-table.element(a,q1)
a<-table.element(a,r$t0[2])
a<-table.element(a,q3)
a<-table.element(a,sqrt(var(r$t[,2])))
a<-table.element(a,q3-q1)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'midrange',header=TRUE)
q1 <- quantile(r$t[,3],0.25)[[1]]
q3 <- quantile(r$t[,3],0.75)[[1]]
a<-table.element(a,q1)
a<-table.element(a,r$t0[3])
a<-table.element(a,q3)
a<-table.element(a,sqrt(var(r$t[,3])))
a<-table.element(a,q3-q1)
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable.tab')
|