Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_bidensity.wasp | ||||||||||||||||||||||||||||||||||||||||||||
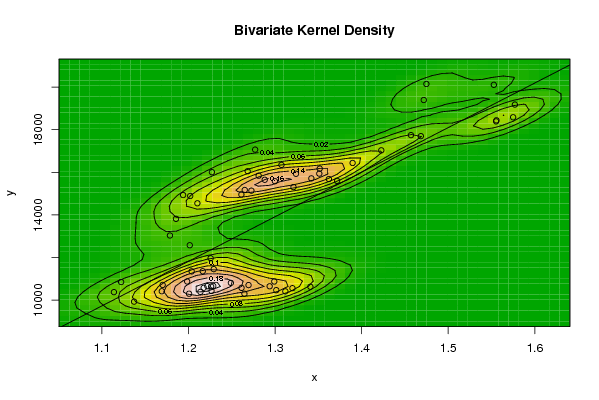
| Title produced by software | Bivariate Kernel Density Estimation | ||||||||||||||||||||||||||||||||||||||||||||
| Date of computation | Thu, 13 Nov 2008 17:47:52 -0700 | ||||||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/14/t1226624038n98b8gb0xnmc8fg.htm/, Retrieved Sat, 18 May 2024 10:24:53 +0000 | ||||||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=24896, Retrieved Sat, 18 May 2024 10:24:53 +0000 | |||||||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | bivariate density eigen tijdreeks | ||||||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 646 | ||||||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||||||
| F [Bivariate Kernel Density Estimation] [Bivariate density...] [2008-11-14 00:47:52] [9f72e095d5529918bf5b0810c01bf6ce] [Current] - MPD [Bivariate Kernel Density Estimation] [Paper - Wisselkoe...] [2010-11-28 15:16:48] [4a7069087cf9e0eda253aeed7d8c30d6] - PD [Bivariate Kernel Density Estimation] [Paper - Werkloosh...] [2010-11-28 16:24:36] [4a7069087cf9e0eda253aeed7d8c30d6] - RMPD [Central Tendency] [Paper - Robustnes...] [2010-11-28 17:01:51] [4a7069087cf9e0eda253aeed7d8c30d6] | |||||||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||||||
1.1372 1.1139 1.1222 1.1692 1.1702 1.2286 1.2613 1.2646 1.2262 1.1985 1.2007 1.2138 1.2266 1.2176 1.2218 1.249 1.2991 1.3408 1.3119 1.3014 1.3201 1.2938 1.2694 1.2165 1.2037 1.2292 1.2256 1.2015 1.1786 1.1856 1.2103 1.1938 1.202 1.2271 1.277 1.265 1.2684 1.2811 1.2727 1.2611 1.2881 1.3213 1.2999 1.3074 1.3242 1.3516 1.3511 1.3419 1.3716 1.3622 1.3896 1.4227 1.4684 1.457 1.4718 1.4748 1.5527 1.575 1.5557 1.5553 1.577 | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries Y: | |||||||||||||||||||||||||||||||||||||||||||||
9924 10371 10846 10413 10709 10662 10570 10297 10635 10872 10296 10383 10431 10574 10653 10805 10872 10625 10407 10463 10556 10646 10702 11353 11346 11451 11964 12574 13031 13812 14544 14931 14886 16005 17064 15168 16050 15839 15137 14954 15648 15305 15579 16348 15928 16171 15937 15713 15594 15683 16438 17032 17696 17745 19394 20148 20108 18584 18441 18391 19178 | |||||||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||||||
par1 <- as(par1,'numeric') | |||||||||||||||||||||||||||||||||||||||||||||