cat1 <- as.numeric(par1) #
cat2<- as.numeric(par2) #
cat3 <- as.numeric(par3)
intercept<-as.logical(par4)
x <- t(x)
x1<-as.numeric(x[,cat1])
f1<-as.character(x[,cat2])
f2 <- as.character(x[,cat3])
xdf<-data.frame(x1,f1, f2)
(V1<-dimnames(y)[[1]][cat1])
(V2<-dimnames(y)[[1]][cat2])
(V3 <-dimnames(y)[[1]][cat3])
names(xdf)<-c('Response', 'Treatment_A', 'Treatment_B')
if(intercept == FALSE) (lmxdf<-lm(Response ~ Treatment_A * Treatment_B- 1, data = xdf) ) else (lmxdf<-lm(Response ~ Treatment_A * Treatment_B, data = xdf) )
(aov.xdf<-aov(lmxdf) )
(anova.xdf<-anova(lmxdf) )
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'ANOVA Model', length(lmxdf$coefficients)+1,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a, lmxdf$call['formula'],length(lmxdf$coefficients)+1,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a, 'means',,TRUE)
for(i in 1:length(lmxdf$coefficients)){
a<-table.element(a, round(lmxdf$coefficients[i], digits=3),,FALSE)
}
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable.tab')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'ANOVA Statistics', 5+1,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a, ' ',,TRUE)
a<-table.element(a, 'Df',,FALSE)
a<-table.element(a, 'Sum Sq',,FALSE)
a<-table.element(a, 'Mean Sq',,FALSE)
a<-table.element(a, 'F value',,FALSE)
a<-table.element(a, 'Pr(>F)',,FALSE)
a<-table.row.end(a)
for(i in 1 : length(rownames(anova.xdf))-1){
a<-table.row.start(a)
a<-table.element(a,rownames(anova.xdf)[i] ,,TRUE)
a<-table.element(a, anova.xdf$Df[1],,FALSE)
a<-table.element(a, round(anova.xdf$'Sum Sq'[i], digits=3),,FALSE)
a<-table.element(a, round(anova.xdf$'Mean Sq'[i], digits=3),,FALSE)
a<-table.element(a, round(anova.xdf$'F value'[i], digits=3),,FALSE)
a<-table.element(a, round(anova.xdf$'Pr(>F)'[i], digits=3),,FALSE)
a<-table.row.end(a)
}
a<-table.row.start(a)
a<-table.element(a, 'Residuals',,TRUE)
a<-table.element(a, anova.xdf$'Df'[i+1],,FALSE)
a<-table.element(a, round(anova.xdf$'Sum Sq'[i+1], digits=3),,FALSE)
a<-table.element(a, round(anova.xdf$'Mean Sq'[i+1], digits=3),,FALSE)
a<-table.element(a, ' ',,FALSE)
a<-table.element(a, ' ',,FALSE)
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable1.tab')
bitmap(file='anovaplot.png')
boxplot(Response ~ Treatment_A + Treatment_B, data=xdf, xlab=V2, ylab=V1, main='Boxplots of ANOVA Groups')
dev.off()
bitmap(file='designplot.png')
xdf2 <- xdf # to preserve xdf make copy for function
names(xdf2) <- c(V1, V2, V3)
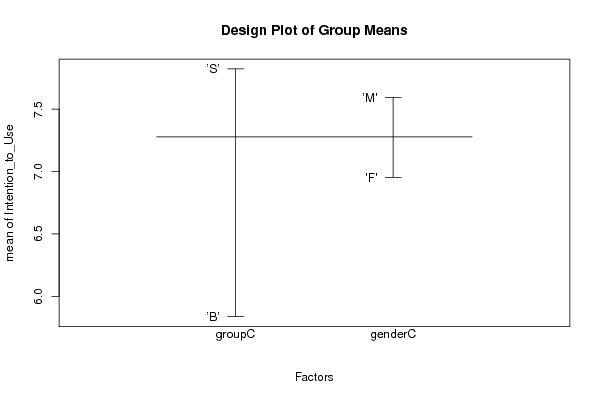
plot.design(xdf2, main='Design Plot of Group Means')
dev.off()
bitmap(file='interactionplot.png')
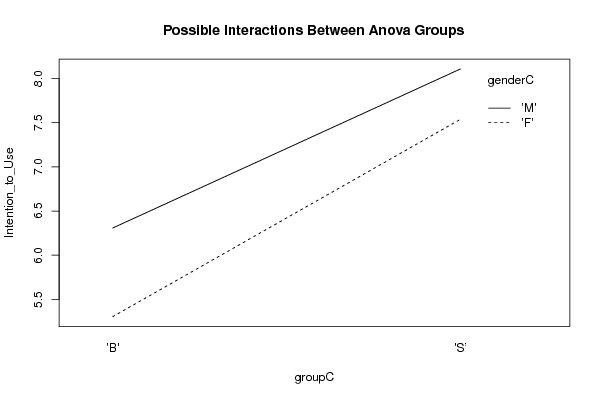
interaction.plot(xdf$Treatment_A, xdf$Treatment_B, xdf$Response, xlab=V2, ylab=V1, trace.label=V3, main='Possible Interactions Between Anova Groups')
dev.off()
if(intercept==TRUE){
thsd<-TukeyHSD(aov.xdf)
names(thsd) <- c(V2, V3, paste(V2, ':', V3, sep=''))
bitmap(file='TukeyHSDPlot.png')
layout(matrix(c(1,2,3,3), 2,2))
plot(thsd, las=1)
dev.off()
}
if(intercept==TRUE){
ntables<-length(names(thsd))
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Tukey Honest Significant Difference Comparisons', 5,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a, ' ', 1, TRUE)
for(i in 1:4){
a<-table.element(a,colnames(thsd[[1]])[i], 1, TRUE)
}
a<-table.row.end(a)
for(nt in 1:ntables){
for(i in 1:length(rownames(thsd[[nt]]))){
a<-table.row.start(a)
a<-table.element(a,rownames(thsd[[nt]])[i], 1, TRUE)
for(j in 1:4){
a<-table.element(a,round(thsd[[nt]][i,j], digits=3), 1, FALSE)
}
a<-table.row.end(a)
}
} # end nt
a<-table.end(a)
table.save(a,file='hsdtable.tab')
}#end if hsd tables
if(intercept==FALSE){
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'TukeyHSD Message', 1,TRUE)
a<-table.row.end(a)
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Must Include Intercept to use Tukey Test ', 1, FALSE)
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable2.tab')
}
library(car)
lt.lmxdf<-levene.test(lmxdf)
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Levenes Test for Homogeneity of Variance', 4,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,' ', 1, TRUE)
for (i in 1:3){
a<-table.element(a,names(lt.lmxdf)[i], 1, FALSE)
}
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Group', 1, TRUE)
for (i in 1:3){
a<-table.element(a,round(lt.lmxdf[[i]][1], digits=3), 1, FALSE)
}
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,' ', 1, TRUE)
a<-table.element(a,lt.lmxdf[[1]][2], 1, FALSE)
a<-table.element(a,' ', 1, FALSE)
a<-table.element(a,' ', 1, FALSE)
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable3.tab')
|