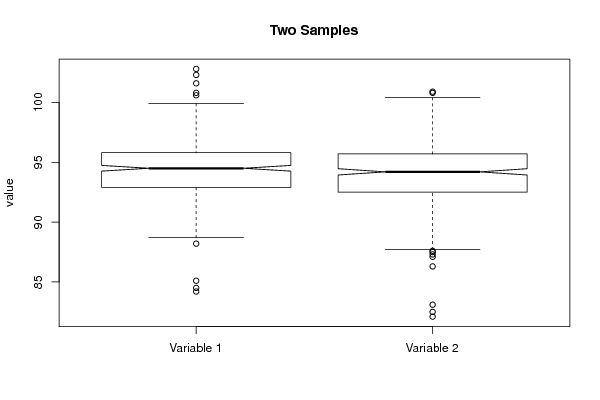
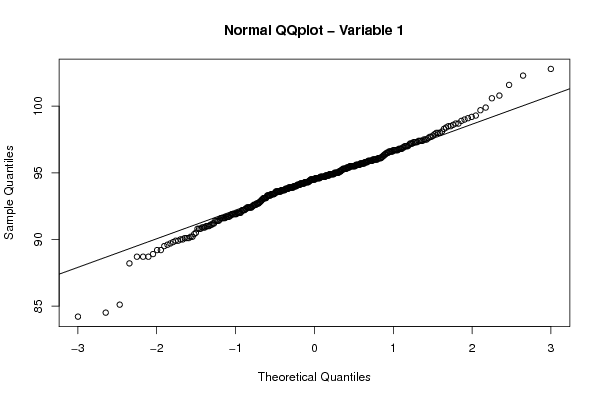
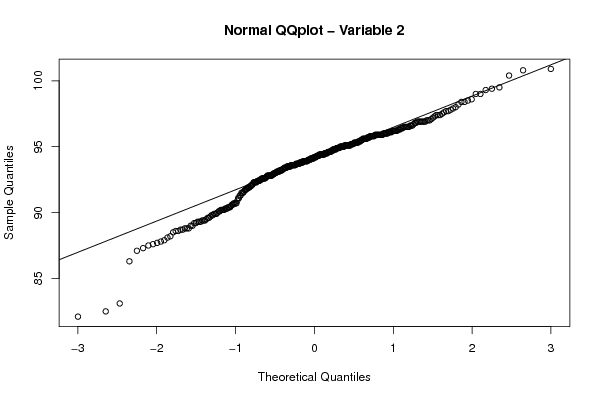
94,8 93,7
95,4 94,8
96,1 96,2
88,7 87,1
91,2 91,6
91,0 88,7
96,6 96,6
91,9 92,1
94,5 92,8
91,8 91,9
96,3 95,1
90,0 89,9
97,0 96,3
97,4 95,5
93,4 94,0
95,0 95,6
95,2 95,3
95,5 94,5
94,3 93,3
94,7 92,4
95,6 95,8
92,4 92,7
91,6 92,0
92,7 92,8
94,6 94,6
94,0 94,2
97,0 96,9
96,6 96,3
93,4 92,3
94,3 92,9
93,7 94,1
91,9 92,6
92,6 92,9
102,8 100,9
92,6 90,6
94,7 94,3
92,3 89,7
95,5 95,9
94,5 93,7
91,2 89,4
96,8 95,9
96,7 96,9
98,0 97,4
92,5 90,7
92,4 92,6
95,0 94,6
94,9 95,0
93,6 93,7
95,7 95,9
94,2 94,1
93,9 92,8
99,9 97,3
94,7 95,0
92,6 90,1
98,3 97,6
93,8 93,6
93,7 93,7
102,3 100,4
99,2 99,0
93,9 93,8
94,7 95,0
90,9 88,5
92,4 92,6
96,9 97,0
95,3 93,6
84,2 82,5
97,4 97,4
94,7 92,6
92,2 92,5
90,5 88,6
97,0 96,9
93,7 93,9
93,8 94,1
93,7 93,2
95,6 96,2
95,9 94,2
96,3 97,4
94,3 94,3
95,8 94,4
99,0 97,1
94,2 91,7
91,5 91,9
93,2 93,4
94,5 94,8
95,3 94,1
93,3 93,9
92,5 90,7
97,1 96,8
95,1 95,9
95,0 95,1
90,2 88,2
90,0 87,7
95,4 94,8
96,1 95,8
92,6 93,2
93,4 93,6
97,4 94,8
96,2 96,0
93,6 93,5
94,1 93,5
96,8 96,5
90,1 87,6
94,6 95,6
93,9 94,0
91,7 89,2
95,7 95,4
98,1 97,9
94,9 94,7
91,4 88,8
94,5 92,0
95,6 95,9
92,4 93,0
99,3 99,4
93,3 93,5
95,0 95,1
99,7 99,5
97,0 97,0
95,7 95,9
94,6 94,9
95,7 95,9
92,3 90,2
91,4 90,3
89,5 87,5
94,7 91,8
95,8 94,5
98,9 98,4
95,1 95,5
93,1 93,2
90,2 90,2
97,3 97,5
89,8 87,8
94,6 93,0
94,7 94,4
94,0 94,4
88,7 89,3
94,0 92,6
96,4 96,4
95,7 95,9
93,4 93,7
97,3 97,0
92,0 91,5
95,5 96,1
93,9 93,9
96,6 96,2
98,0 96,1
94,5 94,8
95,5 95,3
93,3 93,4
94,8 95,0
92,2 90,1
96,7 95,0
94,4 94,9
94,3 93,6
94,5 94,9
90,4 88,1
96,1 95,0
97,5 97,7
93,1 93,3
95,0 94,4
91,6 89,3
93,8 93,9
95,2 95,3
94,8 94,9
93,7 93,1
93,6 93,5
93,6 93,4
93,9 94,2
95,5 94,9
93,8 93,5
94,4 93,9
94,0 93,8
95,7 93,8
93,1 93,1
93,6 95,0
96,0 96,0
94,8 94,4
94,9 95,2
94,6 95,1
89,2 86,3
91,6 91,9
95,3 95,7
95,5 95,6
95,1 95,1
95,9 96,0
97,8 97,8
97,2 94,3
100,6 98,5
93,3 92,2
89,9 90,4
97,5 96,1
92,9 91,3
94,1 94,1
97,6 97,2
101,6 100,8
94,2 94,5
92,7 90,4
93,6 94,0
92,2 92,8
94,2 92,8
92,0 89,5
94,1 94,2
96,0 95,6
94,5 94,5
93,4 93,0
94,5 95,1
91,9 90,0
93,5 93,6
95,8 96,5
93,8 94,2
96,0 96,5
90,8 89,8
88,9 87,3
95,0 95,7
92,4 92,5
94,9 94,4
94,8 92,7
89,6 90,7
94,9 95,2
95,5 96,2
96,1 96,4
95,6 94,3
97,7 98,4
93,9 94,3
95,5 95,4
92,7 92,6
92,0 90,4
95,7 94,0
94,8 93,9
95,8 96,8
92,4 90,7
94,3 92,8
95,6 93,9
93,1 93,5
97,3 96,6
97,7 98,2
98,6 96,7
91,4 89,0
84,5 82,1
94,2 94,6
92,8 92,8
91,9 89,6
93,0 91,1
96,5 95,3
93,5 93,9
96,6 96,9
94,7 95,3
92,9 93,3
94,0 94,7
94,9 94,1
96,7 96,5
90,1 87,9
90,9 91,5
90,8 90,6
93,0 92,3
96,8 95,1
97,4 96,5
89,7 90,2
93,9 94,4
92,0 89,9
95,9 95,4
93,6 93,2
90,8 88,8
94,1 92,4
94,3 94,5
97,5 97,7
98,5 96,6
96,0 95,0
91,4 89,4
96,7 95,1
94,3 94,8
96,6 96,2
85,1 83,1
91,7 89,9
91,0 88,6
91,8 91,8
89,9 90,3
91,6 91,7
89,2 89,3
88,7 88,7
88,2 89,4
94,0 92,3
95,9 96,1
91,0 90,9
100,8 99,0
95,5 95,3
94,9 94,4
96,5 94,4
95,3 95,5
98,4 96,4
95,3 95,8
94,2 94,4
94,3 94,6
99,1 99,3
94,1 93,7
96,4 95,3
95,0 95,1
90,1 90,3
91,6 91,3
93,8 92,4
94,2 92,9
92,8 93,1
94,5 94,6
94,4 93,1
94,6 94,7
95,1 95,4
95,8 95,2
91,9 91,1
96,0 95,8
94,9 95,1
94,6 94,6
94,1 92,1
96,5 95,6
93,3 91,5
95,9 95,1
92,7 92,3
92,0 89,8
90,9 88,8
91,7 92,5
95,4 96,3
94,6 92,8
96,7 96,9
94,7 93,8
95,5 93,6
95,4 93,6
96,9 95,9
93,6 93,4
94,7 93,8
96,0 96,0
91,1 89,0
93,7 93,6
94,8 95,6
92,2 90,5
95,3 95,7
95,0 95,2
93,1 93,1
93,7 93,9
96,8 96,0
98,7 98,6
93,9 93,5
95,3 92,4
92,1 92,3
98,5 96,5
91,1 89,2
94,9 93,0
93,6 94,0
95,9 95,9
97,3 96,9
91,9 90,2
91,7 89,6
97,2 95,6
93,4 93,7
95,9 95,9
96,7 96,9
95,6 96,1
94,6 93,4
96,0 95,8
95,2 95,2
92,4 93,2
97,9 96,0
95,4 95,8
96,2 96,2
97,2 95,8
93,3 93,8
96,1 94,5
95,6 94,7
93,9 93,6
94,2 94,9
98,7 95,7
98,0 98,0
|