library(rpart)
library(partykit)
par1 <- as.numeric(par1)
autoprune <- function ( tree, method='Minimum CV'){
xerr <- tree$cptable[,'xerror']
cpmin.id <- which.min(xerr)
if (method == 'Minimum CV Error plus 1 SD'){
xstd <- tree$cptable[,'xstd']
errt <- xerr[cpmin.id] + xstd[cpmin.id]
cpSE1.min <- which.min( errt < xerr )
mycp <- (tree$cptable[,'CP'])[cpSE1.min]
}
if (method == 'Minimum CV') {
mycp <- (tree$cptable[,'CP'])[cpmin.id]
}
return (mycp)
}
conf.multi.mat <- function(true, new)
{
if ( all( is.na(match( levels(true),levels(new) ) )) )
stop ( 'conflict of vector levels')
multi.t <- list()
for (mylev in levels(true) ) {
true.tmp <- true
new.tmp <- new
left.lev <- levels (true.tmp)[- match(mylev,levels(true) ) ]
levels(true.tmp) <- list ( mylev = mylev, all = left.lev )
levels(new.tmp) <- list ( mylev = mylev, all = left.lev )
curr.t <- conf.mat ( true.tmp , new.tmp )
multi.t[[mylev]] <- curr.t
multi.t[[mylev]]$precision <-
round( curr.t$conf[1,1] / sum( curr.t$conf[1,] ), 2 )
}
return (multi.t)
}
x <- t(y)
k <- length(x[1,])
n <- length(x[,1])
x1 <- cbind(x[,par1], x[,1:k!=par1])
mycolnames <- c(colnames(x)[par1], colnames(x)[1:k!=par1])
colnames(x1) <- mycolnames #colnames(x)[par1]
m <- rpart(as.data.frame(x1))
par2
if (par2 != 'No') {
mincp <- autoprune(m,method=par2)
print(mincp)
m <- prune(m,cp=mincp)
}
m$cptable
bitmap(file='test1.png')
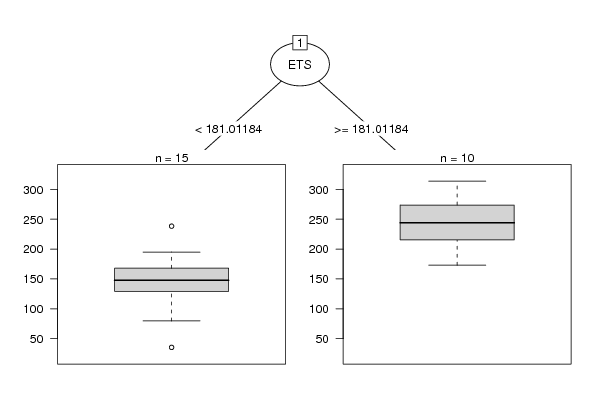
plot(as.party(m),tp_args=list(id=FALSE))
dev.off()
bitmap(file='test2.png')
plotcp(m)
dev.off()
cbind(y=m$y,pred=predict(m),res=residuals(m))
myr <- residuals(m)
myp <- predict(m)
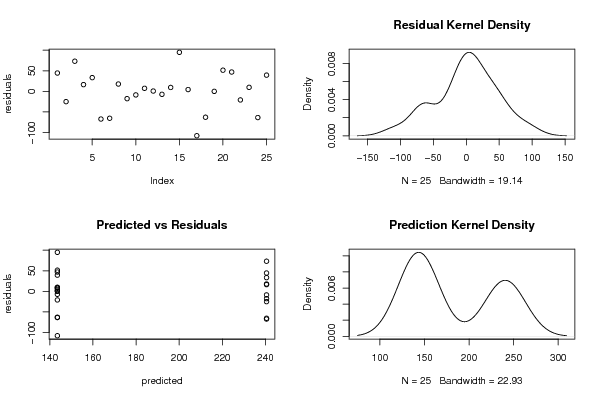
bitmap(file='test4.png')
op <- par(mfrow=c(2,2))
plot(myr,ylab='residuals')
plot(density(myr),main='Residual Kernel Density')
plot(myp,myr,xlab='predicted',ylab='residuals',main='Predicted vs Residuals')
plot(density(myp),main='Prediction Kernel Density')
par(op)
dev.off()
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Model Performance',6,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'#',header=TRUE)
a<-table.element(a,'Complexity',header=TRUE)
a<-table.element(a,'split',header=TRUE)
a<-table.element(a,'relative error',header=TRUE)
a<-table.element(a,'CV error',header=TRUE)
a<-table.element(a,'CV S.D.',header=TRUE)
a<-table.row.end(a)
for (i in 1:length(m$cptable[,1])) {
a<-table.row.start(a)
a<-table.element(a,i,header=TRUE)
a<-table.element(a,round(m$cptable[i,'CP'],3))
a<-table.element(a,m$cptable[i,'nsplit'])
a<-table.element(a,round(m$cptable[i,'rel error'],3))
a<-table.element(a,round(m$cptable[i,'xerror'],3))
a<-table.element(a,round(m$cptable[i,'xstd'],3))
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable.tab')
|