library(party)
library(Hmisc)
par1 <- as.numeric(par1)
par3 <- as.numeric(par3)
x <- data.frame(t(y))
is.data.frame(x)
x <- x[!is.na(x[,par1]),]
k <- length(x[1,])
n <- length(x[,1])
colnames(x)[par1]
x[,par1]
if (par2 == 'kmeans') {
cl <- kmeans(x[,par1], par3)
print(cl)
clm <- matrix(cbind(cl$centers,1:par3),ncol=2)
clm <- clm[sort.list(clm[,1]),]
for (i in 1:par3) {
cl$cluster[cl$cluster==clm[i,2]] <- paste('C',i,sep='')
}
cl$cluster <- as.factor(cl$cluster)
print(cl$cluster)
x[,par1] <- cl$cluster
}
if (par2 == 'quantiles') {
x[,par1] <- cut2(x[,par1],g=par3)
}
if (par2 == 'hclust') {
hc <- hclust(dist(x[,par1])^2, 'cen')
print(hc)
memb <- cutree(hc, k = par3)
dum <- c(mean(x[memb==1,par1]))
for (i in 2:par3) {
dum <- c(dum, mean(x[memb==i,par1]))
}
hcm <- matrix(cbind(dum,1:par3),ncol=2)
hcm <- hcm[sort.list(hcm[,1]),]
for (i in 1:par3) {
memb[memb==hcm[i,2]] <- paste('C',i,sep='')
}
memb <- as.factor(memb)
print(memb)
x[,par1] <- memb
}
if (par2=='equal') {
ed <- cut(as.numeric(x[,par1]),par3,labels=paste('C',1:par3,sep=''))
x[,par1] <- as.factor(ed)
}
table(x[,par1])
colnames(x)
colnames(x)[par1]
x[,par1]
if (par2 == 'none') {
m <- ctree(as.formula(paste(colnames(x)[par1],' ~ .',sep='')),data = x)
}
load(file='createtable')
if (par2 != 'none') {
m <- ctree(as.formula(paste('as.factor(',colnames(x)[par1],') ~ .',sep='')),data = x)
if (par4=='yes') {
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'10-Fold Cross Validation',3+2*par3,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'',1,TRUE)
a<-table.element(a,'Prediction (training)',par3+1,TRUE)
a<-table.element(a,'Prediction (testing)',par3+1,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Actual',1,TRUE)
for (jjj in 1:par3) a<-table.element(a,paste('C',jjj,sep=''),1,TRUE)
a<-table.element(a,'CV',1,TRUE)
for (jjj in 1:par3) a<-table.element(a,paste('C',jjj,sep=''),1,TRUE)
a<-table.element(a,'CV',1,TRUE)
a<-table.row.end(a)
for (i in 1:10) {
ind <- sample(2, nrow(x), replace=T, prob=c(0.9,0.1))
m.ct <- ctree(as.formula(paste('as.factor(',colnames(x)[par1],') ~ .',sep='')),data =x[ind==1,])
if (i==1) {
m.ct.i.pred <- predict(m.ct, newdata=x[ind==1,])
m.ct.i.actu <- x[ind==1,par1]
m.ct.x.pred <- predict(m.ct, newdata=x[ind==2,])
m.ct.x.actu <- x[ind==2,par1]
} else {
m.ct.i.pred <- c(m.ct.i.pred,predict(m.ct, newdata=x[ind==1,]))
m.ct.i.actu <- c(m.ct.i.actu,x[ind==1,par1])
m.ct.x.pred <- c(m.ct.x.pred,predict(m.ct, newdata=x[ind==2,]))
m.ct.x.actu <- c(m.ct.x.actu,x[ind==2,par1])
}
}
print(m.ct.i.tab <- table(m.ct.i.actu,m.ct.i.pred))
numer <- 0
for (i in 1:par3) {
print(m.ct.i.tab[i,i] / sum(m.ct.i.tab[i,]))
numer <- numer + m.ct.i.tab[i,i]
}
print(m.ct.i.cp <- numer / sum(m.ct.i.tab))
print(m.ct.x.tab <- table(m.ct.x.actu,m.ct.x.pred))
numer <- 0
for (i in 1:par3) {
print(m.ct.x.tab[i,i] / sum(m.ct.x.tab[i,]))
numer <- numer + m.ct.x.tab[i,i]
}
print(m.ct.x.cp <- numer / sum(m.ct.x.tab))
for (i in 1:par3) {
a<-table.row.start(a)
a<-table.element(a,paste('C',i,sep=''),1,TRUE)
for (jjj in 1:par3) a<-table.element(a,m.ct.i.tab[i,jjj])
a<-table.element(a,round(m.ct.i.tab[i,i]/sum(m.ct.i.tab[i,]),4))
for (jjj in 1:par3) a<-table.element(a,m.ct.x.tab[i,jjj])
a<-table.element(a,round(m.ct.x.tab[i,i]/sum(m.ct.x.tab[i,]),4))
a<-table.row.end(a)
}
a<-table.row.start(a)
a<-table.element(a,'Overall',1,TRUE)
for (jjj in 1:par3) a<-table.element(a,'-')
a<-table.element(a,round(m.ct.i.cp,4))
for (jjj in 1:par3) a<-table.element(a,'-')
a<-table.element(a,round(m.ct.x.cp,4))
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable3.tab')
}
}
m
bitmap(file='test1.png')
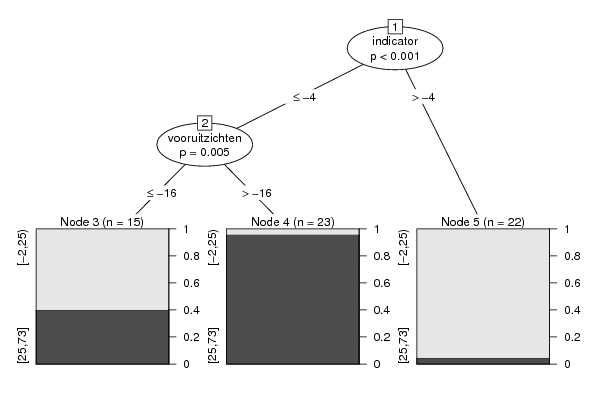
plot(m)
dev.off()
bitmap(file='test1a.png')
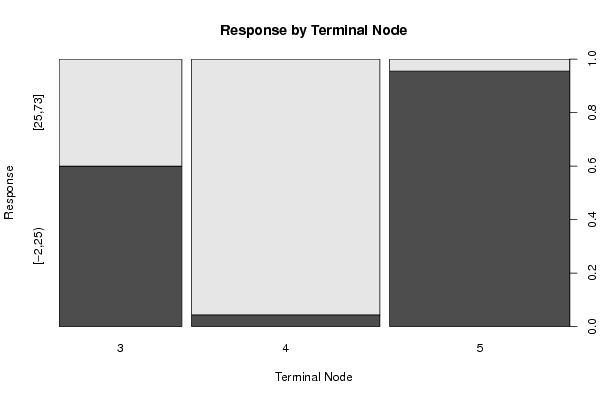
plot(x[,par1] ~ as.factor(where(m)),main='Response by Terminal Node',xlab='Terminal Node',ylab='Response')
dev.off()
if (par2 == 'none') {
forec <- predict(m)
result <- as.data.frame(cbind(x[,par1],forec,x[,par1]-forec))
colnames(result) <- c('Actuals','Forecasts','Residuals')
print(result)
}
if (par2 != 'none') {
print(cbind(as.factor(x[,par1]),predict(m)))
myt <- table(as.factor(x[,par1]),predict(m))
print(myt)
}
bitmap(file='test2.png')
if(par2=='none') {
op <- par(mfrow=c(2,2))
plot(density(result$Actuals),main='Kernel Density Plot of Actuals')
plot(density(result$Residuals),main='Kernel Density Plot of Residuals')
plot(result$Forecasts,result$Actuals,main='Actuals versus Predictions',xlab='Predictions',ylab='Actuals')
plot(density(result$Forecasts),main='Kernel Density Plot of Predictions')
par(op)
}
if(par2!='none') {
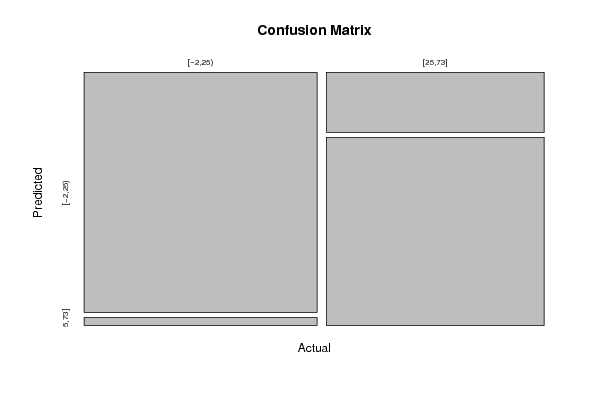
plot(myt,main='Confusion Matrix',xlab='Actual',ylab='Predicted')
}
dev.off()
if (par2 == 'none') {
detcoef <- cor(result$Forecasts,result$Actuals)
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Goodness of Fit',2,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Correlation',1,TRUE)
a<-table.element(a,round(detcoef,4))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'R-squared',1,TRUE)
a<-table.element(a,round(detcoef*detcoef,4))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'RMSE',1,TRUE)
a<-table.element(a,round(sqrt(mean((result$Residuals)^2)),4))
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable1.tab')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Actuals, Predictions, and Residuals',4,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'#',header=TRUE)
a<-table.element(a,'Actuals',header=TRUE)
a<-table.element(a,'Forecasts',header=TRUE)
a<-table.element(a,'Residuals',header=TRUE)
a<-table.row.end(a)
for (i in 1:length(result$Actuals)) {
a<-table.row.start(a)
a<-table.element(a,i,header=TRUE)
a<-table.element(a,result$Actuals[i])
a<-table.element(a,result$Forecasts[i])
a<-table.element(a,result$Residuals[i])
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable.tab')
}
if (par2 != 'none') {
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Confusion Matrix (predicted in columns / actuals in rows)',par3+1,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'',1,TRUE)
for (i in 1:par3) {
a<-table.element(a,paste('C',i,sep=''),1,TRUE)
}
a<-table.row.end(a)
for (i in 1:par3) {
a<-table.row.start(a)
a<-table.element(a,paste('C',i,sep=''),1,TRUE)
for (j in 1:par3) {
a<-table.element(a,myt[i,j])
}
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable2.tab')
}
|