z <- as.data.frame(t(y))
bitmap(file='test1.png')
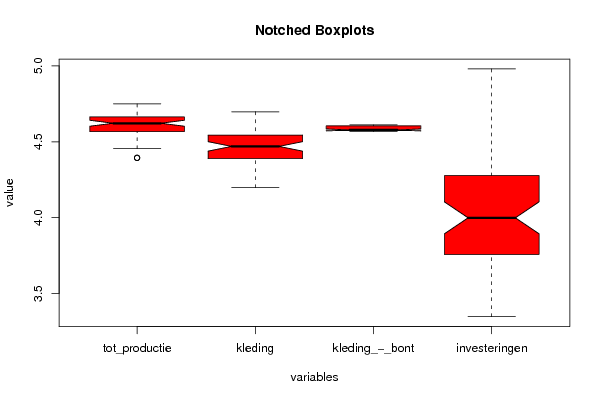
(r<-boxplot(z<-log(z) ,xlab=xlab,ylab=ylab,main=main,notch=TRUE,col=par1))
dev.off()
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,hyperlink('overview.htm','Boxplot statistics','Boxplot overview'),6,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Variable',1,TRUE)
a<-table.element(a,hyperlink('lower_whisker.htm','lower whisker','definition of lower whisker'),1,TRUE)
a<-table.element(a,hyperlink('lower_hinge.htm','lower hinge','definition of lower hinge'),1,TRUE)
a<-table.element(a,hyperlink('central_tendency.htm','median','definitions about measures of central tendency'),1,TRUE)
a<-table.element(a,hyperlink('upper_hinge.htm','upper hinge','definition of upper hinge'),1,TRUE)
a<-table.element(a,hyperlink('upper_whisker.htm','upper whisker','definition of upper whisker'),1,TRUE)
a<-table.row.end(a)
for (i in 1:length(y[,1]))
{
a<-table.row.start(a)
a<-table.element(a,dimnames(t(x))[[2]][i],1,TRUE)
for (j in 1:5)
{
a<-table.element(a,r$stats[j,i])
}
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable.tab')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Boxplot Notches',4,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Variable',1,TRUE)
a<-table.element(a,'lower bound',1,TRUE)
a<-table.element(a,'median',1,TRUE)
a<-table.element(a,'upper bound',1,TRUE)
a<-table.row.end(a)
for (i in 1:length(y[,1]))
{
a<-table.row.start(a)
a<-table.element(a,dimnames(t(x))[[2]][i],1,TRUE)
a<-table.element(a,r$conf[1,i])
a<-table.element(a,r$stats[3,i])
a<-table.element(a,r$conf[2,i])
a<-table.row.end(a)
}
a<-table.end(a)
table.save(a,file='mytable1.tab')
|