Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||
| Author | *Unverified author* | ||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_fitdistrnorm.wasp | ||||||||||||||||||||||||||||||||||||||
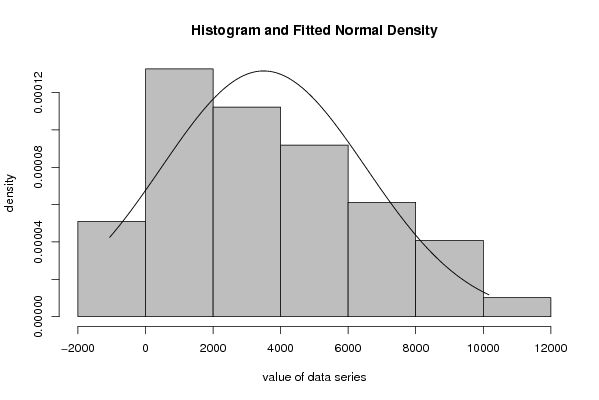
| Title produced by software | Maximum-likelihood Fitting - Normal Distribution | ||||||||||||||||||||||||||||||||||||||
| Date of computation | Thu, 13 Nov 2008 15:37:20 -0700 | ||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/13/t1226615867p1s5tkexy3rt726.htm/, Retrieved Tue, 08 Jul 2025 11:23:07 +0000 | ||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=24873, Retrieved Tue, 08 Jul 2025 11:23:07 +0000 | |||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 264 | ||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||
| - [Bivariate Kernel Density Estimation] [Bel20 en Downjones] [2008-11-12 17:23:23] [74be16979710d4c4e7c6647856088456] F RMPD [Maximum-likelihood Fitting - Normal Distribution] [kelly] [2008-11-12 17:58:06] [74be16979710d4c4e7c6647856088456] F D [Maximum-likelihood Fitting - Normal Distribution] [normality] [2008-11-13 22:37:20] [d41d8cd98f00b204e9800998ecf8427e] [Current] | |||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||
10165 269 708 1362 2271 3516 4775 6334 6150 7794 8851 9721 9676 402 1046 1743 2711 3817 4128 5505 4921 6091 7263 8035 7828 296 500 1134 2061 2737 2959 4113 3494 4518 5470 5664 4717 -606 -615 -1062 -983 -340 467 1580 804 1709 2335 2832 2582 | |||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||
| par1 = 8 ; par2 = 0 ; | |||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||
| par1 = 8 ; par2 = 0 ; | |||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||
library(MASS) | |||||||||||||||||||||||||||||||||||||||