x <- array(x,dim=c(length(x),1))
colnames(x) <- par5
y <- array(y,dim=c(length(y),1))
colnames(y) <- par6
z <- array(z,dim=c(length(z),1))
colnames(z) <- par7
d <- data.frame(cbind(z,y,x))
colnames(d) <- list(par7,par6,par5)
par1 <- as.numeric(par1)
par2 <- as.numeric(par2)
if (par1>500) par1 <- 500
if (par2>500) par2 <- 500
if (par1<10) par1 <- 10
if (par2<10) par2 <- 10
library(GenKern)
library(lattice)
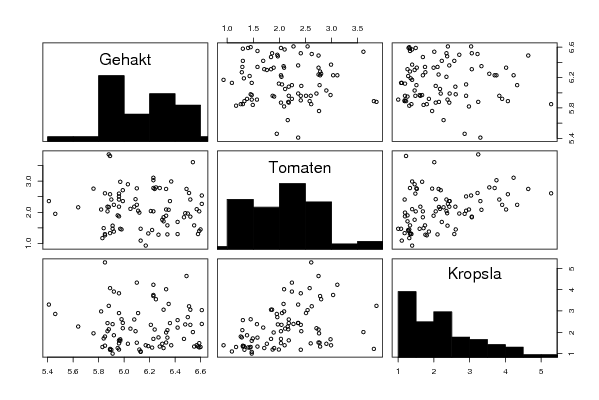
panel.hist <- function(x, ...)
{
usr <- par('usr'); on.exit(par(usr))
par(usr = c(usr[1:2], 0, 1.5) )
h <- hist(x, plot = FALSE)
breaks <- h$breaks; nB <- length(breaks)
y <- h$counts; y <- y/max(y)
rect(breaks[-nB], 0, breaks[-1], y, col='black', ...)
}
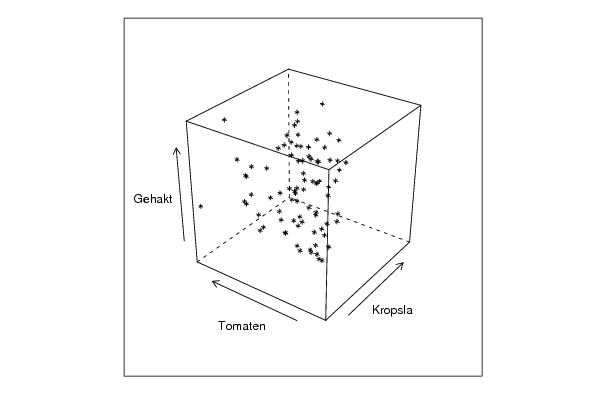
bitmap(file='cloud1.png')
cloud(z~x*y, screen = list(x=-45, y=45, z=35),xlab=par5,ylab=par6,zlab=par7)
dev.off()
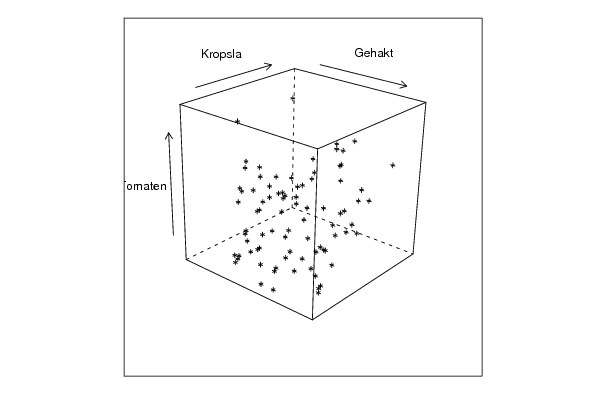
bitmap(file='cloud2.png')
cloud(z~x*y, screen = list(x=35, y=45, z=25),xlab=par5,ylab=par6,zlab=par7)
dev.off()
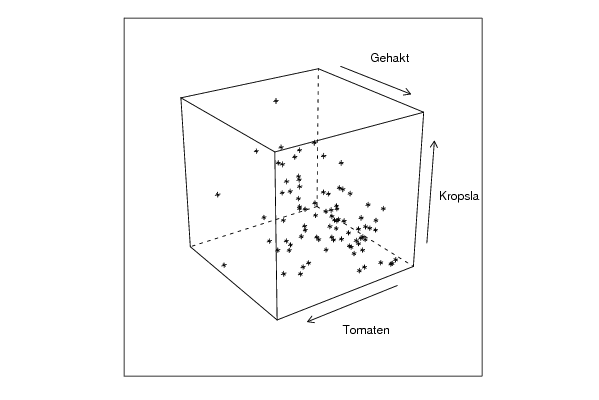
bitmap(file='cloud3.png')
cloud(z~x*y, screen = list(x=35, y=-25, z=90),xlab=par5,ylab=par6,zlab=par7)
dev.off()
bitmap(file='pairs.png')
pairs(d,diag.panel=panel.hist)
dev.off()
x <- as.vector(x)
y <- as.vector(y)
z <- as.vector(z)
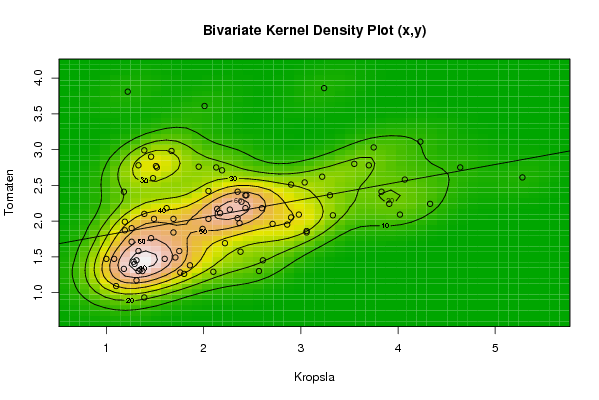
bitmap(file='bidensity1.png')
op <- KernSur(x,y, xgridsize=par1, ygridsize=par2, correlation=cor(x,y), xbandwidth=dpik(x), ybandwidth=dpik(y))
image(op$xords, op$yords, op$zden, col=terrain.colors(100), axes=TRUE,main='Bivariate Kernel Density Plot (x,y)',xlab=par5,ylab=par6)
if (par3=='Y') contour(op$xords, op$yords, op$zden, add=TRUE)
if (par4=='Y') points(x,y)
(r<-lm(y ~ x))
abline(r)
box()
dev.off()
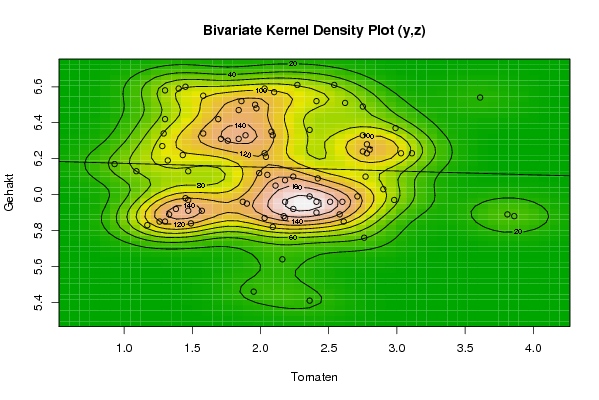
bitmap(file='bidensity2.png')
op <- KernSur(y,z, xgridsize=par1, ygridsize=par2, correlation=cor(y,z), xbandwidth=dpik(y), ybandwidth=dpik(z))
op
image(op$xords, op$yords, op$zden, col=terrain.colors(100), axes=TRUE,main='Bivariate Kernel Density Plot (y,z)',xlab=par6,ylab=par7)
if (par3=='Y') contour(op$xords, op$yords, op$zden, add=TRUE)
if (par4=='Y') points(y,z)
(r<-lm(z ~ y))
abline(r)
box()
dev.off()
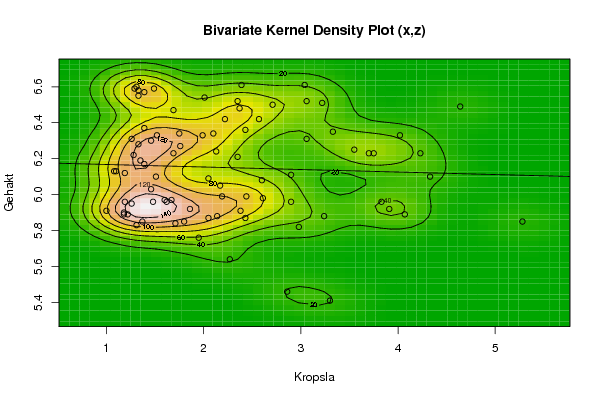
bitmap(file='bidensity3.png')
op <- KernSur(x,z, xgridsize=par1, ygridsize=par2, correlation=cor(x,z), xbandwidth=dpik(x), ybandwidth=dpik(z))
op
image(op$xords, op$yords, op$zden, col=terrain.colors(100), axes=TRUE,main='Bivariate Kernel Density Plot (x,z)',xlab=par5,ylab=par7)
if (par3=='Y') contour(op$xords, op$yords, op$zden, add=TRUE)
if (par4=='Y') points(x,z)
(r<-lm(z ~ x))
abline(r)
box()
dev.off()
|