Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_bidensity.wasp | ||||||||||||||||||||||||||||||||||||||||||||
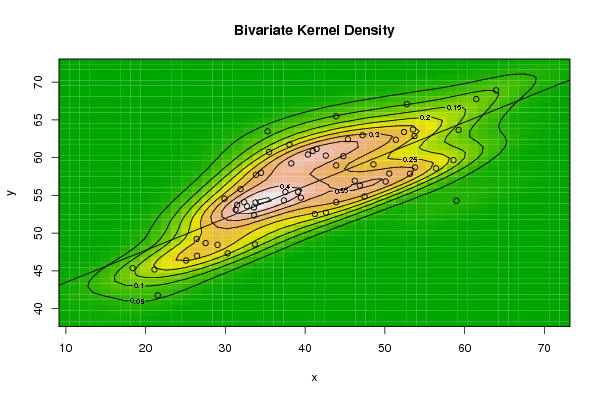
| Title produced by software | Bivariate Kernel Density Estimation | ||||||||||||||||||||||||||||||||||||||||||||
| Date of computation | Mon, 10 Nov 2008 09:53:50 -0700 | ||||||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/10/t1226336158tnxe6uwi92ryezo.htm/, Retrieved Sun, 19 May 2024 10:50:25 +0000 | ||||||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=23134, Retrieved Sun, 19 May 2024 10:50:25 +0000 | |||||||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 183 | ||||||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||||||
| F [Bivariate Kernel Density Estimation] [Bivariate Kernel ...] [2008-11-10 16:53:50] [e08fee3874f3333d6b7a377a061b860d] [Current] F D [Bivariate Kernel Density Estimation] [Bivaritae Kernel ...] [2008-11-10 16:58:43] [819b576fab25b35cfda70f80599828ec] F D [Bivariate Kernel Density Estimation] [Bivariate Kernel ...] [2008-11-10 17:00:38] [819b576fab25b35cfda70f80599828ec] - D [Bivariate Kernel Density Estimation] [paper 1.9 bivaria...] [2008-12-05 19:08:16] [819b576fab25b35cfda70f80599828ec] F RMPD [Partial Correlation] [Partial Correlati...] [2008-11-10 17:08:28] [819b576fab25b35cfda70f80599828ec] - D [Partial Correlation] [Partial Correlati...] [2008-11-10 17:13:48] [819b576fab25b35cfda70f80599828ec] F D [Partial Correlation] [Partial Correlati...] [2008-11-10 17:17:49] [819b576fab25b35cfda70f80599828ec] - RMPD [Trivariate Scatterplots] [Trivariate Scatte...] [2008-11-10 17:21:24] [819b576fab25b35cfda70f80599828ec] - P [Trivariate Scatterplots] [Trivariate Scatte...] [2008-11-10 17:31:18] [819b576fab25b35cfda70f80599828ec] F RMPD [Hierarchical Clustering] [Hierarchical Clus...] [2008-11-10 17:36:33] [819b576fab25b35cfda70f80599828ec] F RM D [Box-Cox Linearity Plot] [Box-Cox linearity...] [2008-11-11 14:51:35] [6fea0e9a9b3b29a63badf2c274e82506] - RMPD [Box-Cox Normality Plot] [Box-Cox Normality...] [2008-11-10 17:45:50] [819b576fab25b35cfda70f80599828ec] F D [Box-Cox Normality Plot] [Box Cox normality...] [2008-11-11 15:12:02] [6fea0e9a9b3b29a63badf2c274e82506] - RMPD [Maximum-likelihood Fitting - Normal Distribution] [Maximum-likelihoo...] [2008-11-10 17:50:35] [819b576fab25b35cfda70f80599828ec] F PD [Maximum-likelihood Fitting - Normal Distribution] [Maximum-likelihoo...] [2008-11-11 15:33:55] [819b576fab25b35cfda70f80599828ec] - RMPD [Trivariate Scatterplots] [Trivariate Scatte...] [2008-11-10 17:27:05] [819b576fab25b35cfda70f80599828ec] | |||||||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||||||
58.972 59.249 63.955 53.785 52.760 44.795 37.348 32.370 32.717 40.974 33.591 21.124 58.608 46.865 51.378 46.235 47.206 45.382 41.227 33.795 31.295 42.625 33.625 21.538 56.421 53.152 53.536 52.408 41.454 38.271 35.306 26.414 31.917 38.030 27.534 18.387 50.556 43.901 48.572 43.899 37.532 40.357 35.489 29.027 34.485 42.598 30.306 26.451 47.460 50.104 61.465 53.726 39.477 43.895 31.481 29.896 33.842 39.120 33.702 25.094 | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries Y: | |||||||||||||||||||||||||||||||||||||||||||||
54.281 63.654 68.918 58.686 67.074 60.183 54.326 54.085 53.564 60.873 53.398 45.164 59.672 56.298 62.361 56.930 62.954 62.431 52.528 54.060 53.093 52.695 52.333 41.747 58.576 57.851 63.721 63.384 61.141 59.231 63.472 49.214 55.816 61.713 48.664 45.351 57.888 54.091 59.098 58.962 55.433 60.403 60.721 48.440 57.981 60.258 47.312 46.980 54.846 56.824 67.744 62.849 54.691 65.461 53.724 54.560 57.722 55.458 48.490 46.362 | |||||||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||||||
par1 <- as(par1,'numeric') | |||||||||||||||||||||||||||||||||||||||||||||