par1 <- as.numeric(par1)
(n <- length(x))
(np <- floor(n / par1))
arr <- array(NA,dim=c(par1,np+1))
darr <- array(NA,dim=c(par1,np+1))
ari <- array(0,dim=par1)
dx <- diff(x)
j <- 0
for (i in 1:n)
{
j = j + 1
ari[j] = ari[j] + 1
arr[j,ari[j]] <- x[i]
darr[j,ari[j]] <- dx[i]
if (j == par1) j = 0
}
ari
arr
darr
arr.mean <- array(NA,dim=par1)
arr.median <- array(NA,dim=par1)
arr.midrange <- array(NA,dim=par1)
for (j in 1:par1)
{
arr.mean[j] <- mean(arr[j,],na.rm=TRUE)
arr.median[j] <- median(arr[j,],na.rm=TRUE)
arr.midrange[j] <- (quantile(arr[j,],0.75,na.rm=TRUE) + quantile(arr[j,],0.25,na.rm=TRUE)) / 2
}
overall.mean <- mean(x)
overall.median <- median(x)
overall.midrange <- (quantile(x,0.75) + quantile(x,0.25)) / 2
bitmap(file='plot1.png')
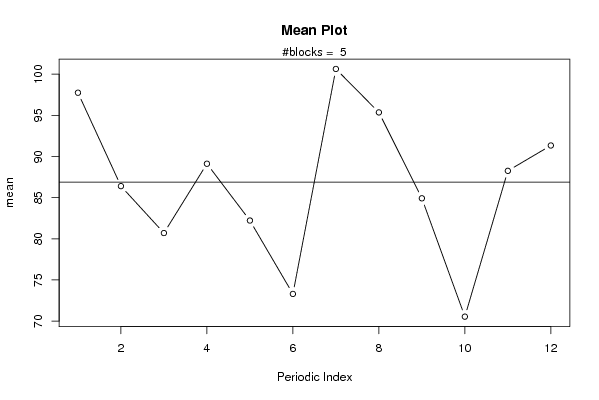
plot(arr.mean,type='b',ylab='mean',main='Mean Plot',xlab='Periodic Index')
mtext(paste('#blocks = ',np))
abline(overall.mean,0)
dev.off()
bitmap(file='plot2.png')
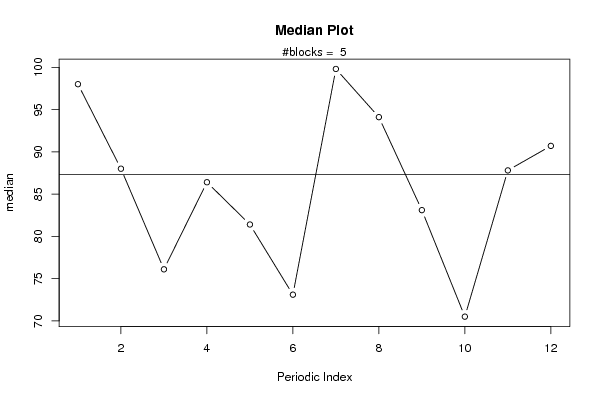
plot(arr.median,type='b',ylab='median',main='Median Plot',xlab='Periodic Index')
mtext(paste('#blocks = ',np))
abline(overall.median,0)
dev.off()
bitmap(file='plot3.png')
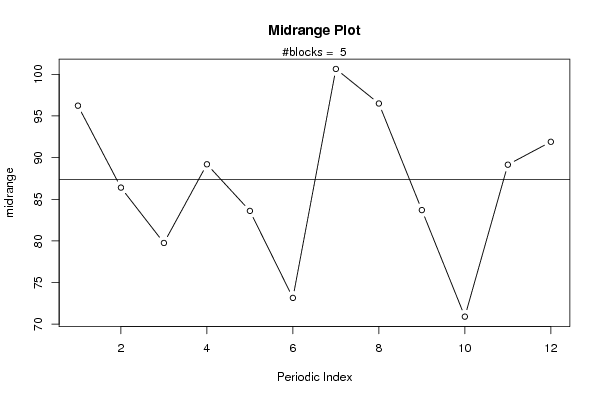
plot(arr.midrange,type='b',ylab='midrange',main='Midrange Plot',xlab='Periodic Index')
mtext(paste('#blocks = ',np))
abline(overall.midrange,0)
dev.off()
bitmap(file='plot4.png')
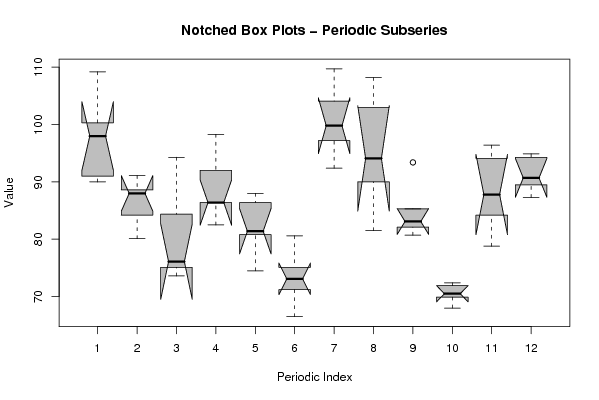
z <- data.frame(t(arr))
names(z) <- c(1:par1)
(boxplot(z,notch=TRUE,col='grey',xlab='Periodic Index',ylab='Value',main='Notched Box Plots - Periodic Subseries'))
dev.off()
bitmap(file='plot4b.png')
z <- data.frame(t(darr))
names(z) <- c(1:par1)
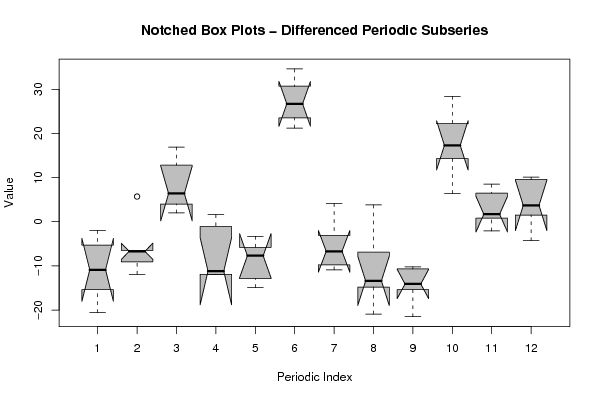
(boxplot(z,notch=TRUE,col='grey',xlab='Periodic Index',ylab='Value',main='Notched Box Plots - Differenced Periodic Subseries'))
dev.off()
bitmap(file='plot5.png')
z <- data.frame(arr)
names(z) <- c(1:np)
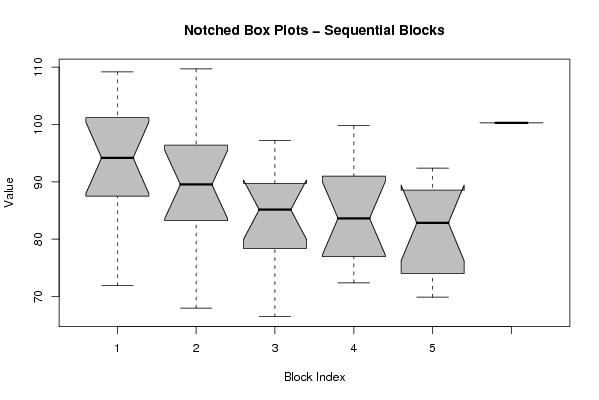
(boxplot(z,notch=TRUE,col='grey',xlab='Block Index',ylab='Value',main='Notched Box Plots - Sequential Blocks'))
dev.off()
bitmap(file='plot6.png')
z <- data.frame(cbind(arr.mean,arr.median,arr.midrange))
names(z) <- list('mean','median','midrange')
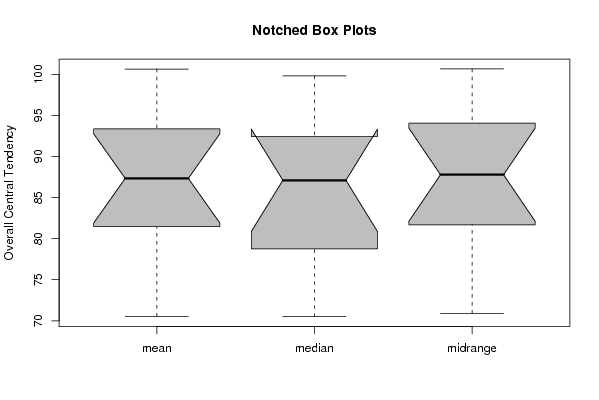
(boxplot(z,notch=TRUE,col='grey',ylab='Overall Central Tendency',main='Notched Box Plots'))
dev.off()
|